
EDGE COMPUTING
Edge Computing, Computación en el Borde o
Informática de borde, es una tecnología
de vanguardia que está redefiniendo la forma en que procesamos datos dentro
de ecosistemas conectados y digitalizados de hoy en día.
Es una tecnología que busca llevar el procesamiento de datos y la ejecución de aplicaciones lo más cerca posible del lugar donde se generan, es decir, consiste en acercar la nube hasta el usuario, hasta el borde mismo (edge, en inglés) de la red.
Recuerda:
- La Nube = Cloud Computing = Servidores (ordenadores) en internet que ofrecen servicio para procesar datos.
- Procesar Datos = Organizarlos, Almacenarlos y transformarlos en información útil.
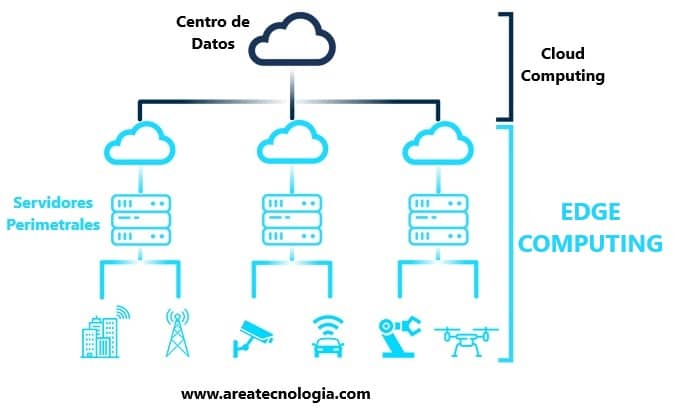
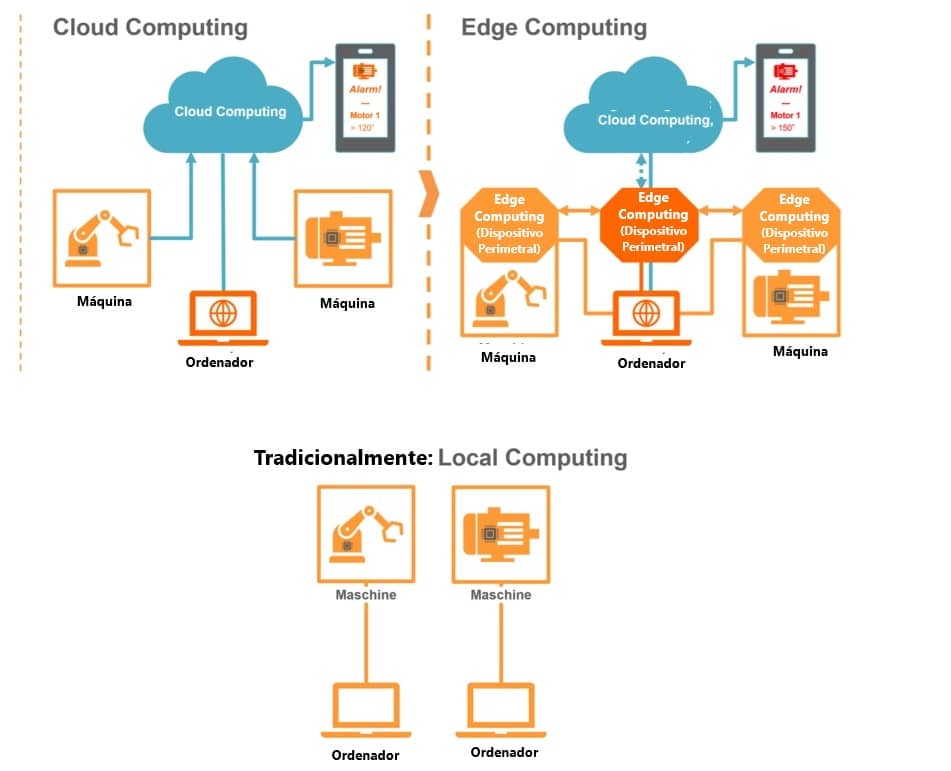
Con el cloud computing los datos generados se envían a través de internet a grandes servidores centralizados y distribuidos por toda la red de internet, es decir por todo el mundo, para que estos los procesen y devuelvan los datos procesados.
Pero con la informática de borde, los datos que se generan no se envian a servidores alejados para que se procesen, se envian a un sitio cercano al dispositivo que los genera, incluso es el propio dispositivo el que los procesa sin necesidad de enviarlos por internet.
Pero....¿qué es exactamente, Cómo Funciona y por qué es importante el edge computing?
Cuando un dispositivo, por ejemplo un sensor en un vehículo autónomo o una cámara de seguridad en una ciudad inteligente genera datos, no resulta práctico enviar todos esta gran cantidad del datos a un servidor o centro de datos centralizado en una ubicación alejada del dispositivo para su procesamiento.
Es mucho más práctico y rápido utilizar edge computing, que lo que hace es utilizar dispositivos pequeños, de bajo consumo y ubicados cerca de la fuente de datos llamados "dispositivos perimetrales o de borde" para enviarles los datos.
Estos dispositivos perimetrales pueden estar en el propio dispositivo o en la fábrica, nave o edificio donde se ubican los aparatos que envían los datos.
Los dispositivos perimetrales también se conocen como servidor de borde o puerta de enlace y son posible gracias a microchips cada vez más potentes que pueden ejecutar incluso cargas de trabajo inteligentes localmente gracias a motores de procesador neuronal y algoritmos de IA (inteligencia artificial) optimizados.
Pero además, los dispositivos perimetrales también pueden estar conectados a una red que les permite comunicarse entre sí o incluso conectados con la nube (internet).
Resumiendo: los datos generados son recogidos y procesados por un dispositivo perimetral, que luego puede enviar los datos procesados a la nube para su posterior análisis o no.
Además, si hay que tranferir datos a la nube, solo se transfieren los datos que realmente se necesitan en la nube (cloud computing) y de esta forma se optimizan mucho todos los procesos.
Utilizar dispositivos perimetrales permite una respuesta casi instantánea a las necesidades de procesamiento, lo que a su vez puede conducir a una mejor toma de decisiones y un mayor rendimiento.
En el pasado reciente, la mayor parte del procesamiento de datos se realizaba en centros de datos o servidores centralizados (cloud computing).
Sin embargo, la propia distancia física provoca retrasos en la transmisión de datos, lo que impide un tiempo de respuesta corto.
Por ejemplo, para una conseguir una transmisión en el rango de milisegundos, el centro de datos no debe estar a más de 100 kilómetros del origen de los datos.
El tiempo de respuesta se puede reducir significativamente acercando físicamente la ubicación del ordenador que procese los datos a la fuente de datos.
En el caso de los datos enviados por un coche inteligente de conducción autónoma se necesita que se procesen de la forma más rápida posible y el edge computing lo hace posible, ya que no sería posible transferir todos los datos recopilados al centro de datos para su procesamiento en tiempo real.
Otro ejemplo, un teléfono inteligente con reconocimiento facial primero tendría que enviar los datos escaneados a una instancia en la nube y luego esperar la respuesta.
Con el edge computing el algoritmo puede procesar los datos localmente en un servidor de borde o puerta de enlace (por ejemplo, el propio teléfono inteligente).
En la industria se está tranfomando ya que gracias al edge computinng puede ofrecer soluciones personalizadas para diferentes escenarios.
En el sector sanitario, la informática de borde permite la monitorización de pacientes en tiempo real y el análisis rápido de datos, algo fundamental para los entornos de cuidados críticos.
La industria manufacturera (fábricas) se beneficia de una mayor eficiencia de la línea de producción, con dispositivos de vanguardia que monitorean y ajustan instantáneamente los procesos, lo que resulta en menos tiempo de inactividad y una mejor calidad del producto.
El comercio minorista está experimentando una transformación a través de la gestión inteligente de inventario y la personalización de la experiencia del cliente, gracias a las rápidas capacidades de procesamiento de datos de la informática de punta.
La industria automotriz, particularmente en el área de los vehículos autónomos, es un excelente ejemplo del impacto de la informática en el borde.
La computación en el borde para vehículos autónomos implica procesar cantidades masivas de datos de sensores en movimiento para tomar decisiones ultrarrápidas, una tarea que la computación en la nube tradicional no puede realizar con tanta eficiencia.
Aquí, el edge computing garantiza la seguridad y mejora los sistemas de navegación.
Además, las iniciativas de ciudades inteligentes están implementando miles de aplicaciones perimetrales que aprovechan la informática perimetral para gestionar todo, desde los flujos de tráfico hasta los niveles de contaminación.
Los sensores y dispositivos de IoT en toda la ciudad recopilan datos que se procesan localmente, lo que permite respuestas en tiempo real a diversos desafíos urbanos.
Este enfoque no sólo mejora la gestión de la ciudad, sino que también aumenta la calidad de vida de los residentes.
Los robots de fabricación conectados en red, las turbinas eólicas o incluso los ascensores pueden reaccionar directamente a los signos de desgaste y solicitar los trabajos de mantenimiento necesarios mediante el mantenimiento predictivo.
Esto es especialmente crucial en aplicaciones que requieren una respuesta inmediata, como la realidad virtual, los juegos online o los sistemas de control en tiempo real.
Además, el Edge computing permite un uso más eficiente de la red, ya que se reduce la necesidad de enviar grandes volúmenes de datos a través de la conexión a Internet, lo que ayuda a optimizar el ancho de banda y reduce los costes asociados con la transferencia de datos.
Otra ventaja importante es la capacidad de funcionamiento independiente del edge computing.
Esto significa que, incluso si se pierde la conexión con la nube o la red, los dispositivos y servidores en la periferia de la red pueden seguir realizando tareas de procesamiento de datos y ejecutando aplicaciones de forma autónoma.
Esto es especialmente útil en entornos donde la conectividad puede ser intermitente o no estar garantizada, como en entornos industriales o en áreas remotas.
Desde una perspectiva de seguridad, los datos en el borde de la red pueden plantear un problema, especialmente cuando el procesamiento de datos involucra varios dispositivos que son significativamente menos seguros que los sistemas centralizados o las instancias en la nube.
Por lo tanto, es esencial que los especialistas involucrados sean conscientes de los posibles riesgos de seguridad de los dispositivos IoT que utilizan servidores de borde y los protejan, por ejemplo con el cifrado de datos y acceso, utilizando redes virtuales, etc.
Además, los diferentes requisitos de conectividad y potencia informática de los dispositivos IoT también pueden afectar la confiabilidad de los dispositivos perimetrales.
Esto hace que la gestión de redundancia y conmutación por error sea obligatoria para los dispositivos que procesan datos en el borde de la red.
Esta es la única manera de garantizar que todos los datos se transmitan y procesen correctamente si falla un solo nodo de la red.
¿Te ha gustado la web Edge Computing? Pulsa en Compartir. Gracias
© Se permite la total o parcial reproducción del contenido, siempre y cuando se reconozca y se enlace a este artículo como la fuente de información utilizada.
Es una tecnología que busca llevar el procesamiento de datos y la ejecución de aplicaciones lo más cerca posible del lugar donde se generan, es decir, consiste en acercar la nube hasta el usuario, hasta el borde mismo (edge, en inglés) de la red.
Recuerda:
- La Nube = Cloud Computing = Servidores (ordenadores) en internet que ofrecen servicio para procesar datos.
- Procesar Datos = Organizarlos, Almacenarlos y transformarlos en información útil.
Con el cloud computing los datos generados se envían a través de internet a grandes servidores centralizados y distribuidos por toda la red de internet, es decir por todo el mundo, para que estos los procesen y devuelvan los datos procesados.
Pero con la informática de borde, los datos que se generan no se envian a servidores alejados para que se procesen, se envian a un sitio cercano al dispositivo que los genera, incluso es el propio dispositivo el que los procesa sin necesidad de enviarlos por internet.
Pero....¿qué es exactamente, Cómo Funciona y por qué es importante el edge computing?
Cómo funciona el Edge Computing
Lo mejor para entenderlo es con un ejemplo.Cuando un dispositivo, por ejemplo un sensor en un vehículo autónomo o una cámara de seguridad en una ciudad inteligente genera datos, no resulta práctico enviar todos esta gran cantidad del datos a un servidor o centro de datos centralizado en una ubicación alejada del dispositivo para su procesamiento.
Es mucho más práctico y rápido utilizar edge computing, que lo que hace es utilizar dispositivos pequeños, de bajo consumo y ubicados cerca de la fuente de datos llamados "dispositivos perimetrales o de borde" para enviarles los datos.
Estos dispositivos perimetrales pueden estar en el propio dispositivo o en la fábrica, nave o edificio donde se ubican los aparatos que envían los datos.
Los dispositivos perimetrales también se conocen como servidor de borde o puerta de enlace y son posible gracias a microchips cada vez más potentes que pueden ejecutar incluso cargas de trabajo inteligentes localmente gracias a motores de procesador neuronal y algoritmos de IA (inteligencia artificial) optimizados.
Pero además, los dispositivos perimetrales también pueden estar conectados a una red que les permite comunicarse entre sí o incluso conectados con la nube (internet).
Resumiendo: los datos generados son recogidos y procesados por un dispositivo perimetral, que luego puede enviar los datos procesados a la nube para su posterior análisis o no.
Además, si hay que tranferir datos a la nube, solo se transfieren los datos que realmente se necesitan en la nube (cloud computing) y de esta forma se optimizan mucho todos los procesos.
Utilizar dispositivos perimetrales permite una respuesta casi instantánea a las necesidades de procesamiento, lo que a su vez puede conducir a una mejor toma de decisiones y un mayor rendimiento.
En el pasado reciente, la mayor parte del procesamiento de datos se realizaba en centros de datos o servidores centralizados (cloud computing).
Sin embargo, la propia distancia física provoca retrasos en la transmisión de datos, lo que impide un tiempo de respuesta corto.
Por ejemplo, para una conseguir una transmisión en el rango de milisegundos, el centro de datos no debe estar a más de 100 kilómetros del origen de los datos.
El tiempo de respuesta se puede reducir significativamente acercando físicamente la ubicación del ordenador que procese los datos a la fuente de datos.
En el caso de los datos enviados por un coche inteligente de conducción autónoma se necesita que se procesen de la forma más rápida posible y el edge computing lo hace posible, ya que no sería posible transferir todos los datos recopilados al centro de datos para su procesamiento en tiempo real.
Otro ejemplo, un teléfono inteligente con reconocimiento facial primero tendría que enviar los datos escaneados a una instancia en la nube y luego esperar la respuesta.
Con el edge computing el algoritmo puede procesar los datos localmente en un servidor de borde o puerta de enlace (por ejemplo, el propio teléfono inteligente).
Donde se Utiliza el Edge Computing
Los campos de aplicación donde más se utiliza hoy en día es en la conducción autónoma, el Internet de las cosas y la Industria 4.0.En la industria se está tranfomando ya que gracias al edge computinng puede ofrecer soluciones personalizadas para diferentes escenarios.
En el sector sanitario, la informática de borde permite la monitorización de pacientes en tiempo real y el análisis rápido de datos, algo fundamental para los entornos de cuidados críticos.
La industria manufacturera (fábricas) se beneficia de una mayor eficiencia de la línea de producción, con dispositivos de vanguardia que monitorean y ajustan instantáneamente los procesos, lo que resulta en menos tiempo de inactividad y una mejor calidad del producto.
El comercio minorista está experimentando una transformación a través de la gestión inteligente de inventario y la personalización de la experiencia del cliente, gracias a las rápidas capacidades de procesamiento de datos de la informática de punta.
La industria automotriz, particularmente en el área de los vehículos autónomos, es un excelente ejemplo del impacto de la informática en el borde.
La computación en el borde para vehículos autónomos implica procesar cantidades masivas de datos de sensores en movimiento para tomar decisiones ultrarrápidas, una tarea que la computación en la nube tradicional no puede realizar con tanta eficiencia.
Aquí, el edge computing garantiza la seguridad y mejora los sistemas de navegación.
Además, las iniciativas de ciudades inteligentes están implementando miles de aplicaciones perimetrales que aprovechan la informática perimetral para gestionar todo, desde los flujos de tráfico hasta los niveles de contaminación.
Los sensores y dispositivos de IoT en toda la ciudad recopilan datos que se procesan localmente, lo que permite respuestas en tiempo real a diversos desafíos urbanos.
Este enfoque no sólo mejora la gestión de la ciudad, sino que también aumenta la calidad de vida de los residentes.
Los robots de fabricación conectados en red, las turbinas eólicas o incluso los ascensores pueden reaccionar directamente a los signos de desgaste y solicitar los trabajos de mantenimiento necesarios mediante el mantenimiento predictivo.
Ventajas del Edge Computin
En primer lugar, reduce la latencia al evitar el envío de datos a través de largas distancias hacia los centros de datos en la nube.Esto es especialmente crucial en aplicaciones que requieren una respuesta inmediata, como la realidad virtual, los juegos online o los sistemas de control en tiempo real.
Además, el Edge computing permite un uso más eficiente de la red, ya que se reduce la necesidad de enviar grandes volúmenes de datos a través de la conexión a Internet, lo que ayuda a optimizar el ancho de banda y reduce los costes asociados con la transferencia de datos.
Otra ventaja importante es la capacidad de funcionamiento independiente del edge computing.
Esto significa que, incluso si se pierde la conexión con la nube o la red, los dispositivos y servidores en la periferia de la red pueden seguir realizando tareas de procesamiento de datos y ejecutando aplicaciones de forma autónoma.
Esto es especialmente útil en entornos donde la conectividad puede ser intermitente o no estar garantizada, como en entornos industriales o en áreas remotas.
Desventajas del Edge Computing
Como ocurre con las nuevas tecnologías, la computación en el borde tiene desventajas.Desde una perspectiva de seguridad, los datos en el borde de la red pueden plantear un problema, especialmente cuando el procesamiento de datos involucra varios dispositivos que son significativamente menos seguros que los sistemas centralizados o las instancias en la nube.
Por lo tanto, es esencial que los especialistas involucrados sean conscientes de los posibles riesgos de seguridad de los dispositivos IoT que utilizan servidores de borde y los protejan, por ejemplo con el cifrado de datos y acceso, utilizando redes virtuales, etc.
Además, los diferentes requisitos de conectividad y potencia informática de los dispositivos IoT también pueden afectar la confiabilidad de los dispositivos perimetrales.
Esto hace que la gestión de redundancia y conmutación por error sea obligatoria para los dispositivos que procesan datos en el borde de la red.
Esta es la única manera de garantizar que todos los datos se transmitan y procesen correctamente si falla un solo nodo de la red.
¿Te ha gustado la web Edge Computing? Pulsa en Compartir. Gracias
© Se permite la total o parcial reproducción del contenido, siempre y cuando se reconozca y se enlace a este artículo como la fuente de información utilizada.
TAMBIEN TE PUEDE INTERESAR
Cloud Computing
Google Drive con Linux
Data WareHouse
DataMining
Como Funciona Internet
DNS
Cosas Tecnologicas
Telefonia Movil
Sistemas Operativos Moviles
TLD los Nuevos Dominios
Internet de las Cosas
WiMax
Servidor y Tipos de Servidores